Vandaag stond de seminar van Fabric Analyst In A Day op het programma, verzorgt door Axians. Een dag vol met duidelijke uitleg, aangevuld met 7 praktijkgerichte labs waarin diverse scenario’s persoonlijk worden doorlopen. Dit met het oog op kennis- en praktijkverbreding.
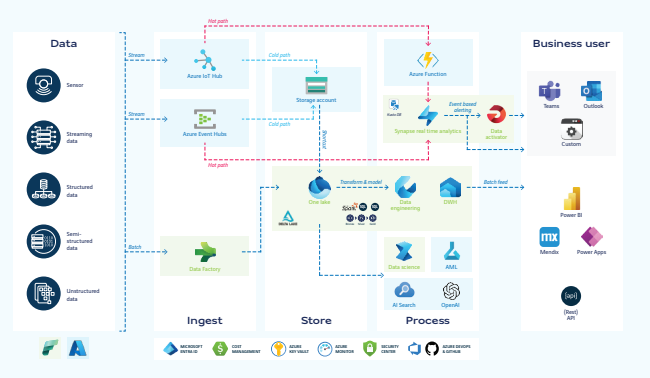
Na een lange dag veel kennis en ervaring opgedaan hoe data van A tot Z wordt ontsloten en uiteindelijk klaar en gebruikt kan worden voor onder andere het gebruik in Power BI. Vooral door het gebruik van ontzettend veel data uit diverse interne én externe bronnen. Hierbij kan uitstekend gebruik worden gemaakt van Mirroring van de diverse databases, waarbij er een kopie wordt gemaakt van bijvoorbeeld derden. Deze data kan vervolgens worden gebruikt voor eigen inzicht.
- OneLake Overview
Het eerste deel stond in teken van de OneLake Overview. Hier werd helder en herkenbaar uitleg gegeven wat het verschil is tussen de diverse databases. Herkenbare stof uit mijn eerdere certificering van DP-900.
Er lag hierbij de nadruk op de vernieuwde mogelijkheden van data waar integratie voor gebruik voor bijvoorbeeld AI is ingebakken in plaats van toegevoegd.
2. Data Enginering
In het blok van Data Enginering kwam voornamelijk het belang van Workspaces naar voren. Goed ontworpen indeling van zowel groepen gebruikers als data-soort vormt de basis voor goed gebruik. Alle onderdelen van Microsoft Fabric werden hierin belicht met hun functie binnen het gehele pakket.
Tijdens de stap Data Enginering werd diep de data in gekeken om te ontdekken wat nodig is in de volgende stappen.

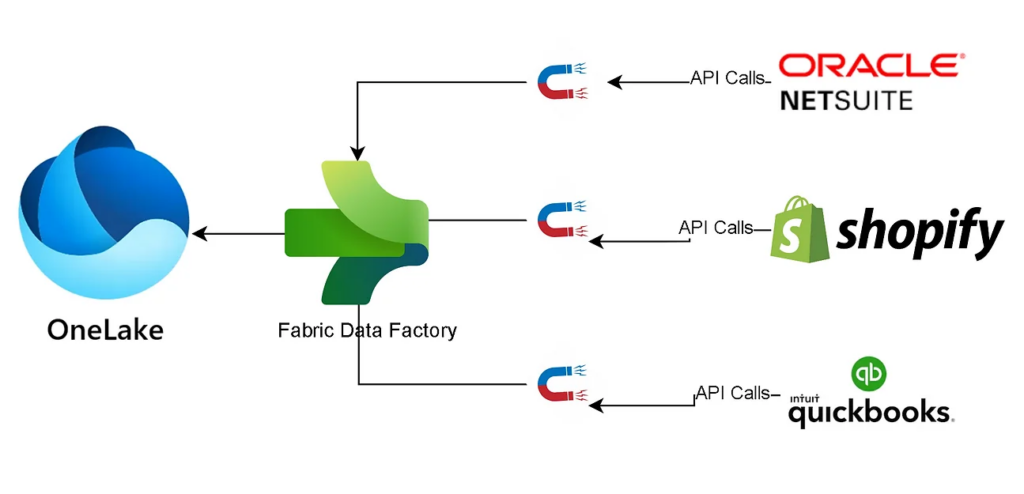
3. Data Factory
Data Factory staat het ETL-proces centraal. Het Extraheren, Transformeren en Laden van de data. Afhankelijk van de bron en het doel, zijn we in dit scenario aan de slag gegaan van gegevens uit bronnen als Onedrive, een open webdatabase, Excel en diverse database vormen. Deze werden vervolgens geplaatst in de Onelake.
4. Data Warehouse
In het onderdeel Data Warehouse werd duidelijk hoe data, welke bewerkt werd in de Data Factory, uiteindelijk terecht komt in de OneLake en deze te benaderen is. Echter daarbij werd ook stil gestaan bij het mogelijk niet goed doorlopen van data, het efficiënter laten doorstromen én het automatiseren van errors of refreshes.
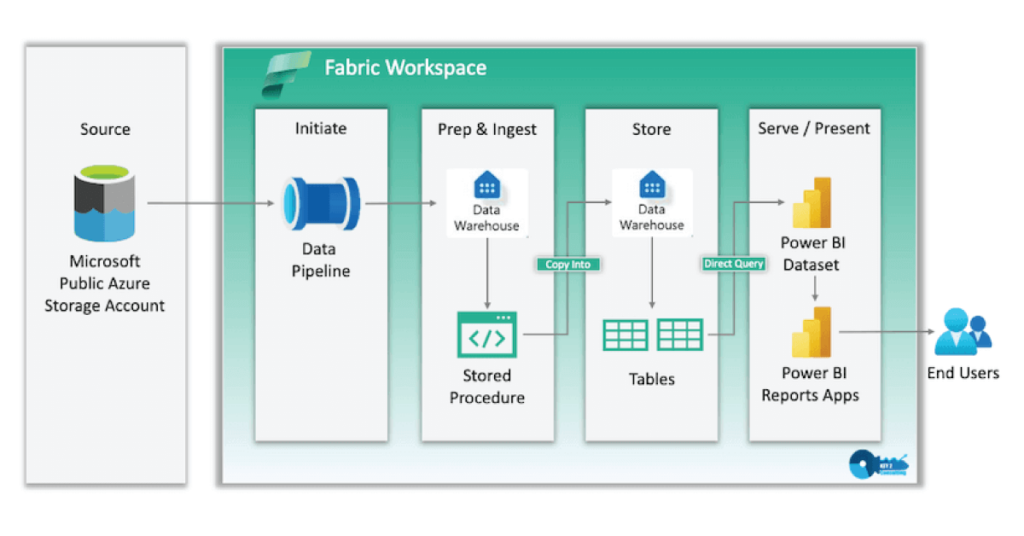
5. Power BI
Hoe data uiteindelijk klaar staat in de Onelake, betekend nog niet het einde van de rit voor een BI Specialist. Hier hoort nog de stap tussen van het maken van Scematic Models en de automatisch gerefreshde rapporten die hierbij horen. In dit onderdeel kwam ook beveiliging, splitsing van rechten en de samenwerking met Data Engineers en Data Scientists aan bod
Maestro – dataplatform van Axians
Als laatste stonden we ook stil bij Maestro, een quick start voor de realisatie van een toekomstbestendig Data & AI
platform op maat met Microsoft technologie. Men biedt hiermee een Foundation wat ervoor zorgt dat de Analytics-oplossing goed landt op de Azure omgeving met oog voor borging van toegang en veiligheid. Meer info: –hier–